
Hugging Face just added DeepInfra to its roster of Inference Providers, and honestly, this is a bigger deal than the usual provider partnership announcements. If you’ve been using the Hub’s serverless inference, you know the options have been growing steadily. DeepInfra brings something a bit different to the table.
DeepInfra positions itself as a cost-effective serverless AI inference platform. Their pricing per token is genuinely competitive — they claim one of the lowest in the industry, and from what I’ve seen, they’re not bluffing. With over 100 models in their catalog, covering everything from LLMs to text-to-image, text-to-video, and embeddings, they cover a lot of ground.
For now, the initial integration focuses on conversational and text-generation tasks. That means you get access to popular open-weight LLMs like DeepSeek V4, Kimi-K2.6, and GLM-5.1 right from the Hub’s model pages. Support for other tasks like image generation and video will roll out later.
How It Actually Works
There are two ways to use DeepInfra through Hugging Face, and this is where it gets practical.
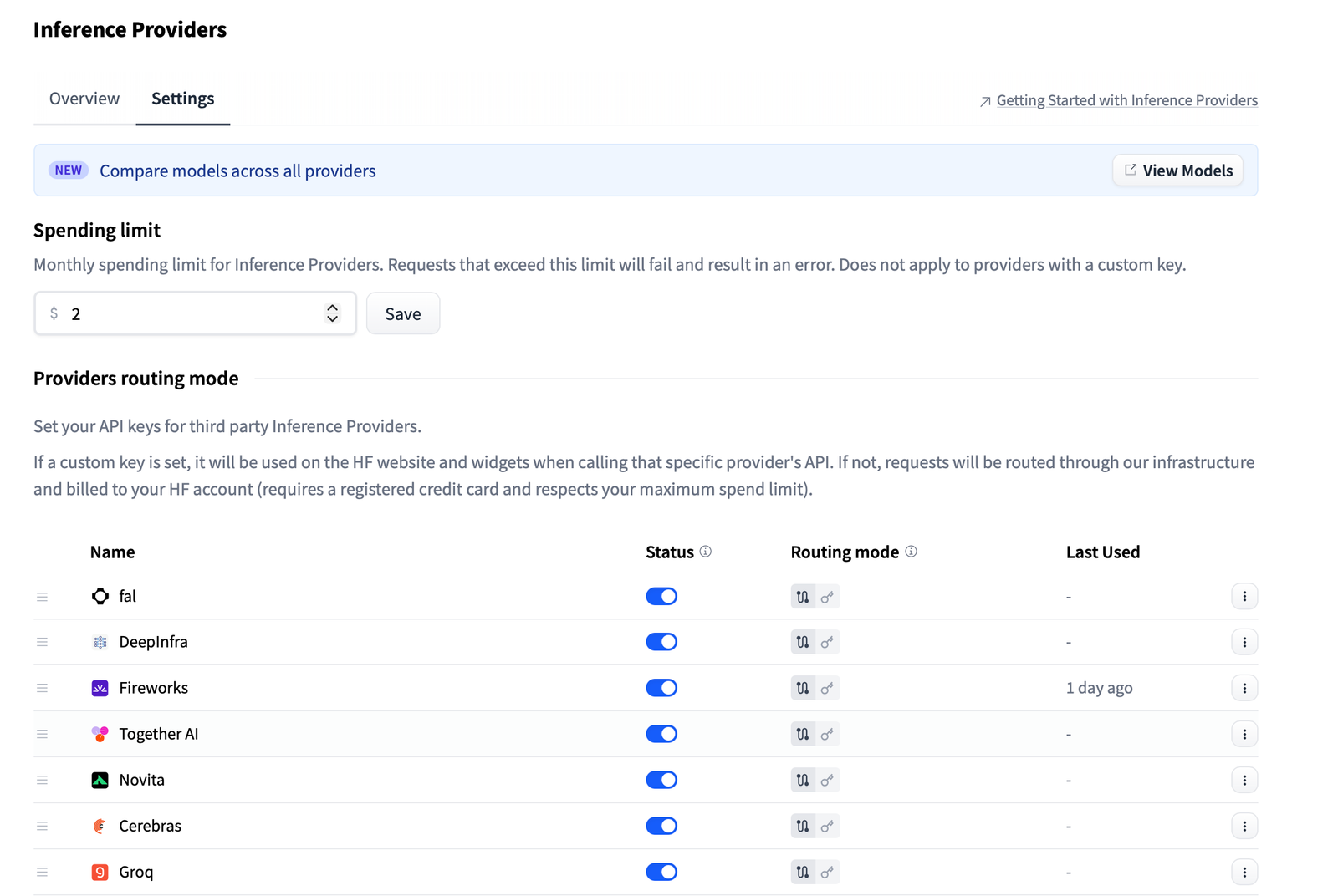
Option 1: Set your own DeepInfra API key. Go to your user account settings, add your key, and requests go directly to DeepInfra. You get billed by DeepInfra directly. This is the straightforward path if you already have a DeepInfra account.
Option 2: Route through Hugging Face. No need for a separate DeepInfra token. You authenticate with your HF token, and charges hit your Hugging Face account. Crucially, there’s no markup — you pay the standard provider API rates. Hugging Face is passing through costs directly, which is refreshingly transparent. They mention possible revenue-sharing agreements in the future, but for now, it’s clean.
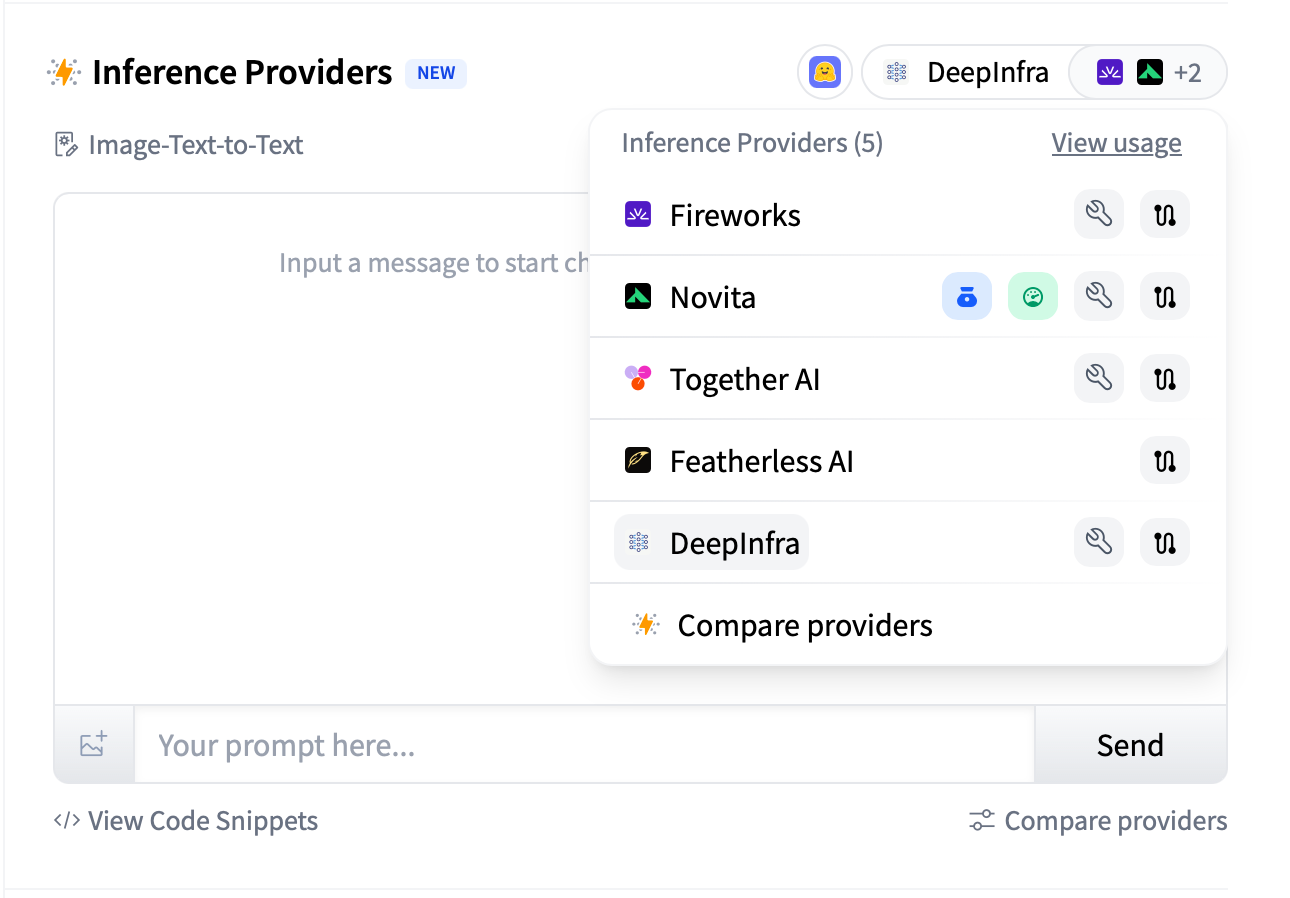
You can also order providers by preference in your settings. This affects which provider appears first in the model page widgets and code snippets. Handy if you have a preferred provider for cost or latency reasons.
SDK Integration and Code Examples
If you’re using the Hugging Face SDKs, DeepInfra just works. The Python SDK (huggingface_hub >= 1.11.2) and the JavaScript SDK (@huggingface/inference) both support it. Here’s what calling DeepSeek V4 Pro through DeepInfra looks like:
Python:
import os
from openai import OpenAI
client = OpenAI(
base_url="https://router.huggingface.co/v1",
api_key=os.environ["HF_TOKEN"],
)
completion = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V4-Pro:deepinfra",
messages=[
{
"role": "user",
"content": "Write a Python function that returns the nth Fibonacci number using memoization."
}
],
)
print(completion.choices[0].message)
JavaScript:
import { OpenAI } from "openai";
const client = new OpenAI({
baseURL: "https://router.huggingface.co/v1",
apiKey: process.env.HF_TOKEN,
});
const chatCompletion = await client.chat.completions.create({
model: "deepseek-ai/DeepSeek-V4-Pro:deepinfra",
messages: [
{
role: "user",
content: "Write a Python function that returns the nth Fibonacci number using memoization.",
},
],
});
console.log(chatCompletion.choices[0].message);
Notice the model string format: model_name:provider_name. This tells the router which provider to use. If you have multiple providers configured, you can switch by changing the suffix.
Agent Integrations
This is where things get interesting if you’re into agent frameworks. Hugging Face Inference Providers are integrated into most major agent harnesses — Pi, OpenCode, Hermes Agents, OpenClaw, and others. You can plug DeepInfra-hosted models straight into your favorite tools without writing glue code. That’s a nice quality-of-life improvement for anyone building agent-based applications.
Billing and Credits
For routed requests (using HF token), you pay the standard provider rates. No markup. For direct requests (using DeepInfra key), you’re billed by DeepInfra. Simple.
PRO users get $2 worth of Inference credits every month, usable across providers. That’s enough for some serious experimentation. Free users get a small quota, but honestly, if you’re doing anything beyond testing, the PRO plan is worth it for the credits alone, plus ZeroGPU and Spaces Dev Mode.
What I Think
Adding DeepInfra makes sense. Their pricing is aggressive, and their model catalog is solid. The fact that they support not just LLMs but also image and video generation (coming soon) means this integration has room to grow.
What I’d like to see next is better visibility into latency and cost comparisons between providers directly in the Hub UI. Right now, you have to know what you’re looking for. If Hugging Face added a side-by-side comparison widget, that would be genuinely useful.
Also, the model string convention (model:provider) works, but it’s a bit ugly. I get why they did it — it’s simple — but it feels like a hack. Maybe a dropdown selector in the UI would be cleaner.
Overall, this is a solid move. If you’re already using Hugging Face for model discovery and deployment, having DeepInfra as another serverless option just gives you more flexibility. And if you’re price-sensitive, DeepInfra’s per-token pricing is worth checking out.
You can find the full list of supported models on DeepInfra’s Hugging Face page. And if you run into issues, the feedback discussion is open.

Comments (0)
Login Log in to comment.
Be the first to comment!