
I’ve been following the agent memory space for a while now, and most solutions feel like they’re stuck in the past. They either log every single action like a surveillance camera or only save the “perfect” workflows from successful runs. Both approaches miss the point. Google’s new ReasoningBank framework, presented at ICLR 2025, takes a different route: it forces agents to actually learn from their screw-ups.
The memory problem nobody’s solving
Agents are everywhere now. They browse the web, edit codebases, manage cloud infrastructure. But watch one for more than a few tasks and you’ll see the same pattern: it makes the same mistake again and again. No learning curve. Just raw repetition.
Existing memory systems are either too granular or too selective. Trajectory memory saves every click, every API call, every keystroke. That’s not wisdom, that’s a log file. Workflow memory only captures successful attempts, which is like a student who only studies the answers they got right. You learn way more from the wrong answers.
ReasoningBank flips this by focusing on higher-level reasoning patterns. Instead of remembering “click button X”, it remembers “always verify the page identifier before scrolling to avoid infinite scroll traps”. That’s a strategy, not a script.
How it actually works
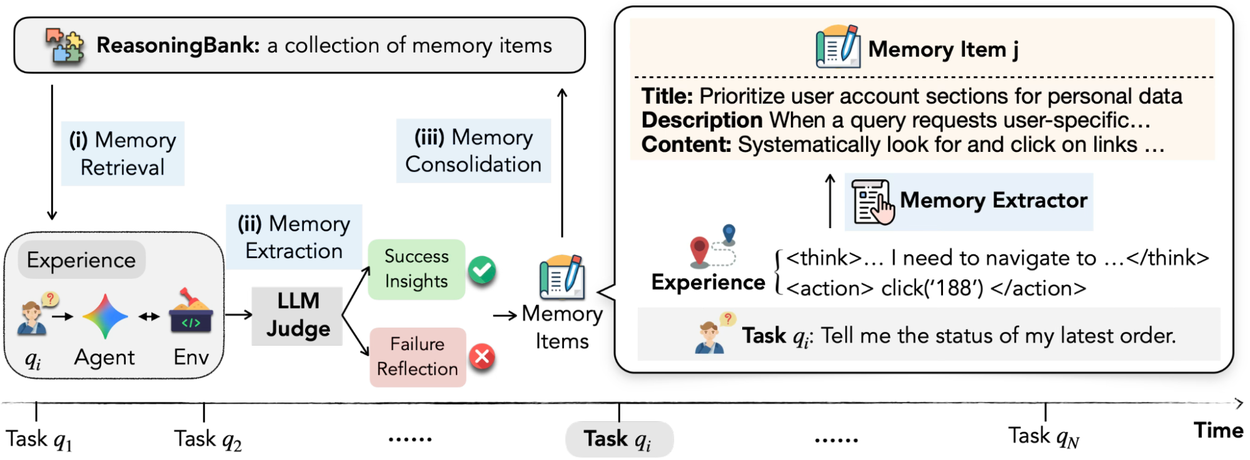
The system runs a continuous loop: retrieve relevant memories, act, self-assess using an LLM-as-a-judge, then extract new insights. It doesn’t require perfect judgment either. The paper notes that ReasoningBank is surprisingly robust against noise in self-evaluation, which is good because LLMs are terrible at being objective about themselves.
Each memory item has three parts: a title (short identifier), a description (summary), and the actual content (distilled reasoning steps or operational insights). The agent pulls these into context before each action, so it’s not carrying around a massive history. Just the relevant patterns.
What I find interesting is that they don’t try to consolidate or merge memories yet. They just append new ones. That’s a smart choice for the initial release — consolidation is a hard problem, and over-engineering the memory management layer early often kills adoption. Leave it for v2.
Learning from failure is the real trick
The standout feature is that ReasoningBank actively mines failures. When an agent screws up, it doesn’t just discard the trajectory. It analyzes what went wrong and distills a preventative lesson. This is where the real value lives.
Think about it: a successful run might teach you one correct path, but a failed run teaches you a whole class of wrong paths to avoid. That’s exponentially more useful. The paper shows that agents using ReasoningBank achieve higher success rates and complete tasks in fewer steps compared to baselines. Efficiency gains come from not repeating the same dumb mistakes.
Where this fits in the bigger picture
This isn’t a silver bullet. The framework still depends on the underlying LLM’s ability to extract meaningful patterns from trajectories. If your base model is weak, your memories will be weak. And the append-only memory store will eventually grow unwieldy for long-running agents. But as a foundation for self-evolving agents, it’s a solid step forward.
I’d like to see more work on memory decay or relevance scoring over time. An agent that’s been running for months shouldn’t be pulling up a lesson from day one about a bug that got fixed in week two. But that’s a refinement problem, not a fundamental flaw.
For now, ReasoningBank gives agent developers a practical way to stop treating their systems like amnesiacs. If you’re building anything that runs more than a few consecutive tasks, you should be looking at this approach. The code is on GitHub, and the paper is worth reading for the evaluation details alone.

Comments (0)
Login Log in to comment.
Be the first to comment!